44 variational autoencoder for deep learning of images labels and captions
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions 2 Variational Autoencoder Image Model 2.1 Image Decoder: Deep Deconvolutional Generative Model Consider Nimages fX(n)gN n=1 , with X (n)2RN x y c; N xand N yrepresent the number of pixels in each spatial dimension, and N cdenotes the number of color bands in the image (N c= 1 for gray-scale images and N c= 3 for RGB images). › csdl › proceedings2017 IEEE International Conference on Computer Vision (ICCV) Deep Clustering via Joint Convolutional Autoencoder Embedding and Relative Entropy Minimization pp. 5747-5756 Deep Scene Image Classification with the MFAFVNet pp. 5757-5765 Learning Bag-of-Features Pooling for Deep Convolutional Neural Networks pp. 5766-5774
HW4: Variational Autoencoders | Bayesian Deep Learning f. (Bonus +5) 1 row x 3 col plot (with caption): Show 3 panels, each one with a 2D visualization of the "encoding" of test images. Color each point by its class label (digit 0 gets one color, digit 1 gets another color, etc). Show at least 100 examples per class label. Problem 2: Fitting VAEs to MNIST to minimize the VI loss

Variational autoencoder for deep learning of images labels and captions
github.com › zziz › pwcGitHub - zziz/pwc: Papers with code. Sorted by stars. Updated ... Deep 360 Pilot: Learning a Deep Agent for Piloting Through 360deg Sports Videos: CVPR: code: 27: Neural Message Passing for Quantum Chemistry: ICML: code: 27: State-Frequency Memory Recurrent Neural Networks: ICML: code: 27: DeepCD: Learning Deep Complementary Descriptors for Patch Representations: ICCV: code: 26: Contrastive Learning for Image ... Variational Mixture-of-Experts Autoencoders for Multi-Modal Deep ... This paper introduces a disentangled multimodal variational autoencoder (DMVAE) that utilizesdisentangled VAE strategy to separate the private and shared latent spaces of multiple modalities, and considers the instance where the latent factor may be of both continuous and discrete nature, leading to the family of general hybrid DMVAE models. 3 PDF Yunchen Pu - Google Scholar Variational autoencoder for deep learning of images, labels and captions. Y Pu, Z Gan, R Henao, X Yuan, C Li, A Stevens, L Carin. Advances in neural information processing systems 29, 2016. 648: ... Symmetric variational autoencoder and connections to adversarial learning. L Chen, S Dai, Y Pu, E Zhou, C Li, Q Su, C Chen, L Carin ...
Variational autoencoder for deep learning of images labels and captions. Variational autoencoder for deep learning of images, labels and ... Variational autoencoder for deep learning of images, labels and captions Pages 2360-2368 ABSTRACT References Comments ABSTRACT A novel variational autoencoder is developed to model images, as well as associated labels or captions. PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions Yunchen Puy, Zhe Gany, Ricardo Henaoy, Xin Yuanz, Chunyuan Liy, Andrew Stevensy and Lawrence Cariny yDepartment of Electrical and Computer Engineering, Duke University {yp42, zg27, r.henao, cl319, ajs104, lcarin}@duke.edu zNokia Bell Labs, Murray Hill xyuan@bell-labs.com Chapter 9 AutoEncoders | Deep Learning and its Applications 9.1 Definition. So far, we have looked at supervised learning applications, for which the training data \({\bf x}\) is associated with ground truth labels \({\bf y}\).For most applications, labelling the data is the hard part of the problem. Autoencoders are a form of unsupervised learning, whereby a trivial labelling is proposed by setting out the output labels \({\bf y}\) to be simply the ... Variational Autoencoder for Deep Learning of Images, Labels and Captions The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code.
Variational Autoencoder for Deep Learning of Images, Labels and Captions The ability of the proposed reference-based variational autoencoders, a novel deep generative model designed to exploit the weak-supervision provided by the reference set, to learn disentangled representations from this minimal form of supervision is validated. 15 PDF View 2 excerpts, cites methods and background Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is de veloped to model images, as well as associated labels or captions. The Deep Generative Decon volutional Network (DGDN) is used as a decoder of the latent image... CiteSeerX — Citation Query Auto-encoding variational Bayes Abstract A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN i ..." Abstract - Add to MetaCart › science › articleGenerative adversarial network in medical imaging: A review Dec 01, 2019 · With the resurgence of deep learning in computer vision starting from 2012 (Krizhevsky et al., 2012), the adoption of deep learning methods in medical imaging has increased dramatically. It is estimated that there were over 400 papers published in 2016 and 2017 in major medical imaging related conference venues and journals ( Litjens et al ...
› pmc › articlesPlant diseases and pests detection based on deep learning: a ... Feb 24, 2021 · At present, deep learning methods have developed many well-known deep neural network models, including deep belief network (DBN), deep Boltzmann machine (DBM), stack de-noising autoencoder (SDAE) and deep convolutional neural network (CNN) . In the area of image recognition, the use of these deep neural network models to realize automate ... › tutorials › imagesImage classification | TensorFlow Core Jan 26, 2022 · This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). The label_batch is a tensor of the shape (32,), these are corresponding labels to the 32 images. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. Configure the dataset for performance › help › deeplearningData Sets for Deep Learning - MATLAB & Simulink - MathWorks Discover data sets for various deep learning tasks. ... Train Variational Autoencoder ... segmentation of images and provides pixel-level labels for 32 ... Deep Generative Models for Image Representation Learning The first part developed a deep generative model joint analysis of images and associated labels or captions. The model is efficiently learned using variational autoencoder. A multilayered (deep) convolutional dictionary representation is employed as a decoder of the
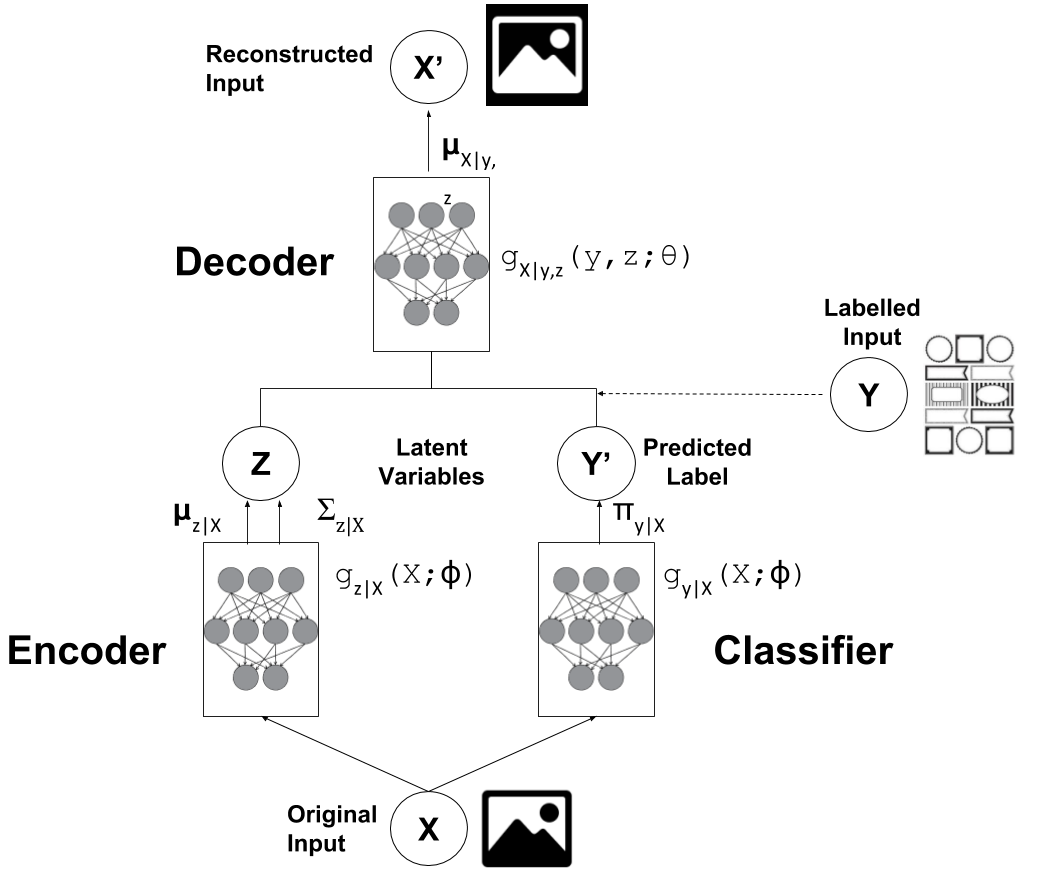
Semi-supervised Learning with Variational Autoencoders | Bounded Rationality
Variational Autoencoders as Generative Models with Keras MNIST dataset | Variational AutoEncoders and Image Generation with Keras Each image in the dataset is a 2D matrix representing pixel intensities ranging from 0 to 255. We will first normalize the pixel values (To bring them between 0 and 1) and then add an extra dimension for image channels (as supported by Conv2D layers from Keras).
Post a Comment for "44 variational autoencoder for deep learning of images labels and captions"